搜索到
560
篇与
的结果
-
-
![【历史上的今天】3 月 28 日:EPROM 的发明者出生;计算机进入艾滋病研究领域]() 【历史上的今天】3 月 28 日:EPROM 的发明者出生;计算机进入艾滋病研究领域 整理 | 王启隆透过「历史上的今天」,从过去看未来,从现在亦可以改变未来。今天是 2023 年 3 月 28 日,1897 年 3 月 28 日,意大利数学家布拉里·福蒂在巴洛摩数学会上提出了的悖论,这个悖论表达了布拉里对于序数理论的质疑和矛盾,人们随后也用他的名字对悖论进行了命名;布拉里·福蒂是近代第一个公开发表的数学悖论,它引起了数学界的兴趣,并导致了以后许多年的热烈讨论。 有几十篇文章讨论悖论问题,极大地推动了对集合论基础的重新审查。回顾计算机历史上的 3 月 28 日,这一天还发生过哪些关键事件呢?1939 年 3 月 28 日:EPROM 的发明者 Dov Frohman 出生 图源:维基百科 多夫·弗罗曼(Dov Frohman)出生于 1939 年 3 月 28 日,他是以色列电气工程师和商业主管,是英特尔公司前副总裁,可擦写可编程只读存储器(EPROM)的发明者;弗罗曼的贡献发展了英特尔在以色列地区的业务,他成为了英特尔以色列公司的创始人和第一任总经理。他还是《Leadership the Hard Way》一书的作者(与罗伯特·霍华德合著)。弗罗曼出生于阿姆斯特丹,当时距二战爆发还有五个月。他的父母是波兰犹太人,他们在 1930 年代初移民到荷兰,以逃避波兰日益高涨的反犹太主义;1942 年,在德国入侵低地国家之后,随着纳粹对荷兰犹太社区的控制收紧,他的父母决定将他们的孩子交给荷兰抵抗运动的熟人,父母将年幼的弗罗曼安置在一个村庄,而自己却在大屠杀中被谋杀。战后,弗罗曼由以色列的亲戚安置,在孤儿院作为“父母在战争中丧生的犹太儿童”度过了几年;在犹太国家成立后,弗罗曼于 1949 年移居以色列。他被亲戚收养,在特拉维夫长大,曾在以色列军队服役。1959 年,他就读于以色列理工学院,攻读电气工程。1963 年从以色列理工学院毕业后,弗罗曼前往美国攻读硕士和博士学位。1965 年,在加州大学伯克利分校获得硕士学位后,弗罗曼开始在仙童半导体公司的研发实验室工作。 图源:维基百科 弗罗曼恰逢仙童半导体公司分崩离析的时刻,在完成博士学位后,他跟随前飞兆半导体经理戈登·摩尔(Gordon Moore)、罗伯特·诺伊斯(Robert Noyce)和安德鲁·格鲁夫(Andrew Grove)来到他们在前一年成立的英特尔公司。正是在对早期英特尔产品的故障进行故障排除时,弗罗曼于 1970 年提出了 EPROM 的概念,这是第一个既可擦除又易于重新编程的非易失性半导体存储器。当时,有两种类型的半导体存储器。随机存取存储器(RAM)芯片易于编程,但当电源关闭时,芯片会失去电荷(以及芯片上编码的信息)。用行业术语来说,RAM 芯片是不稳定的。相比之下,只读存储器(ROM)芯片是非易失性的——也就是说,芯片中编码的信息是固定不变的。但对 ROM 存储器进行编程的过程既费时又麻烦。通常,数据必须在工厂“烧录”,而一烧录就要花费数周的时间;且芯片一旦被编程,ROM 芯片中的数据就不能被改变。而 EPROM 不一样,它是非易失性和可重新编程的。它是导致闪存技术创新和发展的催化剂。EPROM 也是个人计算机行业的一项重要创新。英特尔创始人戈登·摩尔称其“在微型计算机行业的发展中与微处理器本身一样重要”。直到 1980 年代,EPROM 仍然是英特尔最赚钱的产品。发明 EPROM 后, 弗罗曼离开英特尔,在加纳库马西的科技大学开始教授电气工程;他于 1973 年回到英特尔,但此时的他已经有了一个长期的愿景:回到以色列,在那里建立一个高科技研究中心。 图源:维基百科 1974 年,弗罗曼帮助英特尔在海法建立了一个小型芯片设计中心——这也是英特尔在美国以外的第一个设计中心。回到以色列后,弗罗曼在耶路撒冷希伯来大学应用科学学院任教,同时担任英特尔的顾问。1985 年,在与以色列政府就在耶路撒冷建立半导体工厂进行谈判后,英特尔第一次在美国以外的地方建立了分部——英特尔以色列;弗罗曼当即决定离开希伯来大学,成为英特尔以色列的总经理。在 2022 年的今天,英特尔以色列成为了该公司全球无线技术研发的总部。它开发了公司的迅驰移动计算技术,为笔记本电脑和先进的微处理器产品提供动力。它也是芯片制造的主要中心。2008 年,该公司在 Kiryat Gat 开设了第二家半导体工厂——投资 35 亿美元,拥有 7000 名员工。2007 年,英特尔以色列的出口总额为 14 亿美元,约占以色列电子和信息产业出口总额的 8.5%。弗罗曼于 2001 年从英特尔退休,2018 年,他被任命为计算机历史博物馆研究员,他还是以色列科学与人文学院的成员。资料来源:维基百科1986 年 3 月 28 日:计算机进入艾滋病研究领域 图源:维基百科 1986 年 3 月 28 日,在治疗艾滋病流行的早期进展中,新泽西州罗氏实验室的一个团队在《科学》杂志上发表了一篇文章,讨论了 HIV 蛋白酶分子的理论基础,随即成为头条新闻。计算机投入医疗研究已经有了许多年的历史,而设计针对病毒的分子是药物研究人员使用计算机的众多方法之一。艾滋病毒在受感染者中继续变异,在此期间,可以根据其不断变化的遗传状况确定感染的来源和时间线。与此同时,目前的计算机模拟已经能够从数据中成功地推断和预测艾滋病毒的传播。艾滋病毒的快速变异能力是疫苗难以战胜它的主要原因之一,但它对流行病学研究也很有价值。根据流行病学资料,艾滋病毒感染与血液、母婴传播和性接触有关。这些科学家使用系统发育分析来研究细胞之间复杂的进化关系,从而进一步估计艾滋病毒是如何传播的。计算机的力量在如今的这场疫情也发挥了不可忽视的力量,而疫情本身也对计算机行业产生了前所未有的影响;疫情期间,当大部分人的注意力转移到线上,互联网科技得以广泛应用;科技产品“数据化”、线上教育的留学、商家转战线上、医疗的自动化……你认为未来计算机行业的发展趋势会是怎么样的呢?欢迎在评论区分享你认为有可能的发展方向。以史为镜,可以知兴替。计算机科学发展至今,有许多至关重要的事件、人物。在《新程序员:我们的技术时代,我们的程序人生》中,来自四十余位技术人跨越半个世纪,用代码敲出一个个真实的程序人生故事!扫描或点击《新程序员:我们的技术时代,我们的程序人生》订阅!
【历史上的今天】3 月 28 日:EPROM 的发明者出生;计算机进入艾滋病研究领域 整理 | 王启隆透过「历史上的今天」,从过去看未来,从现在亦可以改变未来。今天是 2023 年 3 月 28 日,1897 年 3 月 28 日,意大利数学家布拉里·福蒂在巴洛摩数学会上提出了的悖论,这个悖论表达了布拉里对于序数理论的质疑和矛盾,人们随后也用他的名字对悖论进行了命名;布拉里·福蒂是近代第一个公开发表的数学悖论,它引起了数学界的兴趣,并导致了以后许多年的热烈讨论。 有几十篇文章讨论悖论问题,极大地推动了对集合论基础的重新审查。回顾计算机历史上的 3 月 28 日,这一天还发生过哪些关键事件呢?1939 年 3 月 28 日:EPROM 的发明者 Dov Frohman 出生 图源:维基百科 多夫·弗罗曼(Dov Frohman)出生于 1939 年 3 月 28 日,他是以色列电气工程师和商业主管,是英特尔公司前副总裁,可擦写可编程只读存储器(EPROM)的发明者;弗罗曼的贡献发展了英特尔在以色列地区的业务,他成为了英特尔以色列公司的创始人和第一任总经理。他还是《Leadership the Hard Way》一书的作者(与罗伯特·霍华德合著)。弗罗曼出生于阿姆斯特丹,当时距二战爆发还有五个月。他的父母是波兰犹太人,他们在 1930 年代初移民到荷兰,以逃避波兰日益高涨的反犹太主义;1942 年,在德国入侵低地国家之后,随着纳粹对荷兰犹太社区的控制收紧,他的父母决定将他们的孩子交给荷兰抵抗运动的熟人,父母将年幼的弗罗曼安置在一个村庄,而自己却在大屠杀中被谋杀。战后,弗罗曼由以色列的亲戚安置,在孤儿院作为“父母在战争中丧生的犹太儿童”度过了几年;在犹太国家成立后,弗罗曼于 1949 年移居以色列。他被亲戚收养,在特拉维夫长大,曾在以色列军队服役。1959 年,他就读于以色列理工学院,攻读电气工程。1963 年从以色列理工学院毕业后,弗罗曼前往美国攻读硕士和博士学位。1965 年,在加州大学伯克利分校获得硕士学位后,弗罗曼开始在仙童半导体公司的研发实验室工作。 图源:维基百科 弗罗曼恰逢仙童半导体公司分崩离析的时刻,在完成博士学位后,他跟随前飞兆半导体经理戈登·摩尔(Gordon Moore)、罗伯特·诺伊斯(Robert Noyce)和安德鲁·格鲁夫(Andrew Grove)来到他们在前一年成立的英特尔公司。正是在对早期英特尔产品的故障进行故障排除时,弗罗曼于 1970 年提出了 EPROM 的概念,这是第一个既可擦除又易于重新编程的非易失性半导体存储器。当时,有两种类型的半导体存储器。随机存取存储器(RAM)芯片易于编程,但当电源关闭时,芯片会失去电荷(以及芯片上编码的信息)。用行业术语来说,RAM 芯片是不稳定的。相比之下,只读存储器(ROM)芯片是非易失性的——也就是说,芯片中编码的信息是固定不变的。但对 ROM 存储器进行编程的过程既费时又麻烦。通常,数据必须在工厂“烧录”,而一烧录就要花费数周的时间;且芯片一旦被编程,ROM 芯片中的数据就不能被改变。而 EPROM 不一样,它是非易失性和可重新编程的。它是导致闪存技术创新和发展的催化剂。EPROM 也是个人计算机行业的一项重要创新。英特尔创始人戈登·摩尔称其“在微型计算机行业的发展中与微处理器本身一样重要”。直到 1980 年代,EPROM 仍然是英特尔最赚钱的产品。发明 EPROM 后, 弗罗曼离开英特尔,在加纳库马西的科技大学开始教授电气工程;他于 1973 年回到英特尔,但此时的他已经有了一个长期的愿景:回到以色列,在那里建立一个高科技研究中心。 图源:维基百科 1974 年,弗罗曼帮助英特尔在海法建立了一个小型芯片设计中心——这也是英特尔在美国以外的第一个设计中心。回到以色列后,弗罗曼在耶路撒冷希伯来大学应用科学学院任教,同时担任英特尔的顾问。1985 年,在与以色列政府就在耶路撒冷建立半导体工厂进行谈判后,英特尔第一次在美国以外的地方建立了分部——英特尔以色列;弗罗曼当即决定离开希伯来大学,成为英特尔以色列的总经理。在 2022 年的今天,英特尔以色列成为了该公司全球无线技术研发的总部。它开发了公司的迅驰移动计算技术,为笔记本电脑和先进的微处理器产品提供动力。它也是芯片制造的主要中心。2008 年,该公司在 Kiryat Gat 开设了第二家半导体工厂——投资 35 亿美元,拥有 7000 名员工。2007 年,英特尔以色列的出口总额为 14 亿美元,约占以色列电子和信息产业出口总额的 8.5%。弗罗曼于 2001 年从英特尔退休,2018 年,他被任命为计算机历史博物馆研究员,他还是以色列科学与人文学院的成员。资料来源:维基百科1986 年 3 月 28 日:计算机进入艾滋病研究领域 图源:维基百科 1986 年 3 月 28 日,在治疗艾滋病流行的早期进展中,新泽西州罗氏实验室的一个团队在《科学》杂志上发表了一篇文章,讨论了 HIV 蛋白酶分子的理论基础,随即成为头条新闻。计算机投入医疗研究已经有了许多年的历史,而设计针对病毒的分子是药物研究人员使用计算机的众多方法之一。艾滋病毒在受感染者中继续变异,在此期间,可以根据其不断变化的遗传状况确定感染的来源和时间线。与此同时,目前的计算机模拟已经能够从数据中成功地推断和预测艾滋病毒的传播。艾滋病毒的快速变异能力是疫苗难以战胜它的主要原因之一,但它对流行病学研究也很有价值。根据流行病学资料,艾滋病毒感染与血液、母婴传播和性接触有关。这些科学家使用系统发育分析来研究细胞之间复杂的进化关系,从而进一步估计艾滋病毒是如何传播的。计算机的力量在如今的这场疫情也发挥了不可忽视的力量,而疫情本身也对计算机行业产生了前所未有的影响;疫情期间,当大部分人的注意力转移到线上,互联网科技得以广泛应用;科技产品“数据化”、线上教育的留学、商家转战线上、医疗的自动化……你认为未来计算机行业的发展趋势会是怎么样的呢?欢迎在评论区分享你认为有可能的发展方向。以史为镜,可以知兴替。计算机科学发展至今,有许多至关重要的事件、人物。在《新程序员:我们的技术时代,我们的程序人生》中,来自四十余位技术人跨越半个世纪,用代码敲出一个个真实的程序人生故事!扫描或点击《新程序员:我们的技术时代,我们的程序人生》订阅! -
![Java分布式全局ID(一)]() Java分布式全局ID(一) 随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。 如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高 并发大流量的电商业务场景下,微服务更是企业首选的架构模式。随着业务发展壮大,用户量暴 涨,单节点处理能力就会成为瓶颈,如果并发量居高不下,服务器很容易因负载过高而导致崩溃 宕机。出于高并发,高可用的考虑,项目就应该演变到分布式架构了。然而分布式环境下我们又 会面临更多的挑战需要去应对。比如: 1、分布式系统中接口繁多,重试机制必不可少,接口幂等性问题? 2、如果下单、付款分布在不同的服务上,如何保证跨服务事务? 3、高并发场景下资源共享问题? 4、分库分表后,引发了ID重复问题? 那么,我们需要如何解决分布式呢? 文章目录🔥分布式全局唯一ID🔥分布式全局唯一ID解决方案🔥什么是雪花算法SonwFlake🔥雪花算法SonwFlake落地实现🔥雪花算法SonwFlake落地实现之Mybatis Plus🔥分布式全局唯一ID何为 ID日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。为什么需要分布式ID随着系统数据量越来越大,单数据库压力太大无法维持性能,所以可能就需要变成一主多从这样读写分离,随着继续扩大一主多从也无法支撑了。这时就需要分库分表,这样的话就会出现不同库表之间的数据id不能再依赖数据库自增的id,而需要外部一种方式生成全局统一的唯一id。分布式ID需要满足什么条件?唯一性:全局必须唯一。?高性能:不能在生成id上浪费过多的时间,使其成为功能的性能瓶颈。?高可用:必须保证可用性。?趋势递增:这个不是必须的,但是最好还是满足,因为比如innodb索引就是按照键值排序的,所以有序性可以让维护索引的效率提高。🔥分布式全局唯一ID解决方案UUIDJava本身提供了UUID,这是一个唯一的字符串,它可以不依赖其他工具在本地生成。优点?代码实现简单?本地生成,没有性能问题?全球唯一的,数据迁移容易缺点?每次生成的ID是无序的,不满足趋势递增?UUID是字符串,而且比较长,占用空间大,查询效率低?ID没有含义,可读性差依靠数据库自增字段生成一个数据库压力大就搞多个数据库,之后搞一个Step步长的概念,每个数据库的自增起始值不同,但是他们的增长Step相同。如下图所示。优点?返回的分布式ID是趋势递增的id唯一。解决了单点问题,即使一个宕机其他的还可以提供服务。缺点?单点压力还是很大,因为DB本身写操作就耗时间。最主要的问题还是扩容困难,比如要加一台DB3是很难加进来的,除非停机,将所有DB的id进行修改,同时修改步长。号段模式它没有采用新插入记录返回id的方案,而是一个业务类型就是一行数据,用一行数据来维护这个业务的自增id。服务来修改这行数据的max_id,比如当前max_id值是0,那么来给max_id加上1000,如果返回成功,就代表这个服务获得了1-1000这段分布式id,之后将这段缓存在服务内部,用完之后再来表中取。优点?效率很高,db的压力减小,而且一张表可以维护很多业务的分布式id。缺点?复杂性提高,需要系统为了这个生成方案对号段进行缓存。Redis自增key方案通过incr命令让一个key自增,自增后的值作为分布式id。优点?有序递增,可读性强?性能较高缺点?占用带宽,依赖Redis雪花算法(SnowFlake)SnowFlake生成的是一个Long类型的值,Long类型的数据占用8个字节,也就是64位。SnowFlake将64进行拆分,每个部分具有不同的含义,当然机器码、序列号的位数可以自定义也可以。优点?本地生成,不依赖中间件。?生成的分布式id足够小,只有8个字节,而且是递增的。缺点?时钟回拨问题,强烈依赖于服务器的时间,如果时间出现时间回拨就可能出现重复的id。🔥什么是雪花算法SonwFlakeSnowflake常称为雪花算法,是Twitter开源的分布式ID生成算法,生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。雪花算法作用?生成的所有的id都是随着时间递增?分布式系统内不会产生重复的idSnowFlake算法优点?高性能高可用:生成时不依赖于数据库,完全在内存中生成?高吞吐:每秒钟能生成数百个的自增ID? ID自增:存入数据库中,索引效率高SnowFlake算法的缺点依赖系统时间,如果系统时间被回调,或者改变,可能会造成ID冲突或者重复雪花算法组成注意:?1位,不用,二进制中的最高位是符号位,1表示负数,0表示正数,由于我们生成的雪花算法都是正整数,所以这里是0 。?41位,这里的时间戳是表示的是从起始时间算起,到生成id时间所经历的时间戳,也就是(当前时间戳-起始时间戳(固定)) 这里一共是41位,范围就是(0~ 2^41-1),这么大的毫秒数转化成时间就是大约69年 。?10位,这里的10位代表工作机器id,一共可以部署在(2^10=1024)台机器上面,10位又可以分为前面五位是数据中心id(0~31),后面五位是机器id(0-31) 。?共12位,序列位,一共可用(0 ~ 2^12-1)共4096个数字。🔥雪花算法SonwFlake落地实现Hutool简介Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。引入相关依赖hutool工具包已经提供雪花算法ID生成的工具类。<!-- https://mvnrepository.com/artifact/cn.hutool/hu tool-all --> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.13</version> </dependency> Snowflake分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。//参数1为机器标识 //参数2为数据标识 Snowflake snowflake = IdUtil.getSnowflake(1, 1); long id = snowflake.nextId(); //简单使用 long id = IdUtil.getSnowflakeNextId(); String id = snowflake.getSnowflakeNextIdStr(); 雪花算法SpringBoot引用config文件package com.example.demo.config; import cn.hutool.core.lang.Snowflake; import cn.hutool.core.net.NetUtil; import cn.hutool.core.util.IdUtil; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; @Slf4j @Component public class IdGeneratorSnowflake { private long workerId = 0; //第几号机房 private long datacenterId = 1; //第几号机器 private Snowflake snowflake = IdUtil.getSnowflake(workerId, datacenterId); @PostConstruct //构造后开始执行,加载初始化工作 public void init(){ try{ //获取本机的ip地址编码 workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr()); log.info("当前机器的workerId: " + workerId); }catch (Exception e){ e.printStackTrace(); log.warn("当前机器的workerId获取失败 - ---> " + e); workerId = NetUtil.getLocalhostStr().hashCode(); } } /** 分布式全局唯一ID实现_雪花算法SonwFlake落地实现之 Mybatis Plus 初始化工程 * 生成id * @return */ public synchronized long snowflakeId(){ return snowflake.nextId(); } } 🔥雪花算法SonwFlake落地实现之Mybatis Plus初始化工程<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-bootstarter</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-bootstarter</artifactId> <version>3.4.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connectorjava</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-startertest</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintageengine</artifactId> </exclusion> </exclusions> </dependency> </dependencies> 编写相关配置在 application.yml 配置文件中添加 MySQL 数据库的相关配置:spring.datasource.driver-classname=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.66.1 00:3306/test?serverTimezone=UTC spring.datasource.username=root spring.datasource.password=123456 开启MapperScan扫描在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:@SpringBootApplication @MapperScan("com.itbaizhan.sonwflake.mapper") public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 编码编写实体类 User.java@Data public class User { @TableId(type = IdType.ASSIGN_ID)// 雪花算法 private Long id; private String name; private Integer age; private String email; } 编写Mapperpublic interface UserMapper extends BaseMapper<User> { } 添加测试类 @Test void createUser() { User user = new User(); user.setName("张三"); user.setAge(18); user.setEmail("23472@qq.com"); userMapper.insert(user); }
Java分布式全局ID(一) 随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。 如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高 并发大流量的电商业务场景下,微服务更是企业首选的架构模式。随着业务发展壮大,用户量暴 涨,单节点处理能力就会成为瓶颈,如果并发量居高不下,服务器很容易因负载过高而导致崩溃 宕机。出于高并发,高可用的考虑,项目就应该演变到分布式架构了。然而分布式环境下我们又 会面临更多的挑战需要去应对。比如: 1、分布式系统中接口繁多,重试机制必不可少,接口幂等性问题? 2、如果下单、付款分布在不同的服务上,如何保证跨服务事务? 3、高并发场景下资源共享问题? 4、分库分表后,引发了ID重复问题? 那么,我们需要如何解决分布式呢? 文章目录🔥分布式全局唯一ID🔥分布式全局唯一ID解决方案🔥什么是雪花算法SonwFlake🔥雪花算法SonwFlake落地实现🔥雪花算法SonwFlake落地实现之Mybatis Plus🔥分布式全局唯一ID何为 ID日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。为什么需要分布式ID随着系统数据量越来越大,单数据库压力太大无法维持性能,所以可能就需要变成一主多从这样读写分离,随着继续扩大一主多从也无法支撑了。这时就需要分库分表,这样的话就会出现不同库表之间的数据id不能再依赖数据库自增的id,而需要外部一种方式生成全局统一的唯一id。分布式ID需要满足什么条件?唯一性:全局必须唯一。?高性能:不能在生成id上浪费过多的时间,使其成为功能的性能瓶颈。?高可用:必须保证可用性。?趋势递增:这个不是必须的,但是最好还是满足,因为比如innodb索引就是按照键值排序的,所以有序性可以让维护索引的效率提高。🔥分布式全局唯一ID解决方案UUIDJava本身提供了UUID,这是一个唯一的字符串,它可以不依赖其他工具在本地生成。优点?代码实现简单?本地生成,没有性能问题?全球唯一的,数据迁移容易缺点?每次生成的ID是无序的,不满足趋势递增?UUID是字符串,而且比较长,占用空间大,查询效率低?ID没有含义,可读性差依靠数据库自增字段生成一个数据库压力大就搞多个数据库,之后搞一个Step步长的概念,每个数据库的自增起始值不同,但是他们的增长Step相同。如下图所示。优点?返回的分布式ID是趋势递增的id唯一。解决了单点问题,即使一个宕机其他的还可以提供服务。缺点?单点压力还是很大,因为DB本身写操作就耗时间。最主要的问题还是扩容困难,比如要加一台DB3是很难加进来的,除非停机,将所有DB的id进行修改,同时修改步长。号段模式它没有采用新插入记录返回id的方案,而是一个业务类型就是一行数据,用一行数据来维护这个业务的自增id。服务来修改这行数据的max_id,比如当前max_id值是0,那么来给max_id加上1000,如果返回成功,就代表这个服务获得了1-1000这段分布式id,之后将这段缓存在服务内部,用完之后再来表中取。优点?效率很高,db的压力减小,而且一张表可以维护很多业务的分布式id。缺点?复杂性提高,需要系统为了这个生成方案对号段进行缓存。Redis自增key方案通过incr命令让一个key自增,自增后的值作为分布式id。优点?有序递增,可读性强?性能较高缺点?占用带宽,依赖Redis雪花算法(SnowFlake)SnowFlake生成的是一个Long类型的值,Long类型的数据占用8个字节,也就是64位。SnowFlake将64进行拆分,每个部分具有不同的含义,当然机器码、序列号的位数可以自定义也可以。优点?本地生成,不依赖中间件。?生成的分布式id足够小,只有8个字节,而且是递增的。缺点?时钟回拨问题,强烈依赖于服务器的时间,如果时间出现时间回拨就可能出现重复的id。🔥什么是雪花算法SonwFlakeSnowflake常称为雪花算法,是Twitter开源的分布式ID生成算法,生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。雪花算法作用?生成的所有的id都是随着时间递增?分布式系统内不会产生重复的idSnowFlake算法优点?高性能高可用:生成时不依赖于数据库,完全在内存中生成?高吞吐:每秒钟能生成数百个的自增ID? ID自增:存入数据库中,索引效率高SnowFlake算法的缺点依赖系统时间,如果系统时间被回调,或者改变,可能会造成ID冲突或者重复雪花算法组成注意:?1位,不用,二进制中的最高位是符号位,1表示负数,0表示正数,由于我们生成的雪花算法都是正整数,所以这里是0 。?41位,这里的时间戳是表示的是从起始时间算起,到生成id时间所经历的时间戳,也就是(当前时间戳-起始时间戳(固定)) 这里一共是41位,范围就是(0~ 2^41-1),这么大的毫秒数转化成时间就是大约69年 。?10位,这里的10位代表工作机器id,一共可以部署在(2^10=1024)台机器上面,10位又可以分为前面五位是数据中心id(0~31),后面五位是机器id(0-31) 。?共12位,序列位,一共可用(0 ~ 2^12-1)共4096个数字。🔥雪花算法SonwFlake落地实现Hutool简介Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。引入相关依赖hutool工具包已经提供雪花算法ID生成的工具类。<!-- https://mvnrepository.com/artifact/cn.hutool/hu tool-all --> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.13</version> </dependency> Snowflake分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。//参数1为机器标识 //参数2为数据标识 Snowflake snowflake = IdUtil.getSnowflake(1, 1); long id = snowflake.nextId(); //简单使用 long id = IdUtil.getSnowflakeNextId(); String id = snowflake.getSnowflakeNextIdStr(); 雪花算法SpringBoot引用config文件package com.example.demo.config; import cn.hutool.core.lang.Snowflake; import cn.hutool.core.net.NetUtil; import cn.hutool.core.util.IdUtil; import lombok.extern.slf4j.Slf4j; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; @Slf4j @Component public class IdGeneratorSnowflake { private long workerId = 0; //第几号机房 private long datacenterId = 1; //第几号机器 private Snowflake snowflake = IdUtil.getSnowflake(workerId, datacenterId); @PostConstruct //构造后开始执行,加载初始化工作 public void init(){ try{ //获取本机的ip地址编码 workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr()); log.info("当前机器的workerId: " + workerId); }catch (Exception e){ e.printStackTrace(); log.warn("当前机器的workerId获取失败 - ---> " + e); workerId = NetUtil.getLocalhostStr().hashCode(); } } /** 分布式全局唯一ID实现_雪花算法SonwFlake落地实现之 Mybatis Plus 初始化工程 * 生成id * @return */ public synchronized long snowflakeId(){ return snowflake.nextId(); } } 🔥雪花算法SonwFlake落地实现之Mybatis Plus初始化工程<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-bootstarter</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-bootstarter</artifactId> <version>3.4.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connectorjava</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-startertest</artifactId> <scope>test</scope> <exclusions> <exclusion> <groupId>org.junit.vintage</groupId> <artifactId>junit-vintageengine</artifactId> </exclusion> </exclusions> </dependency> </dependencies> 编写相关配置在 application.yml 配置文件中添加 MySQL 数据库的相关配置:spring.datasource.driver-classname=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.66.1 00:3306/test?serverTimezone=UTC spring.datasource.username=root spring.datasource.password=123456 开启MapperScan扫描在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:@SpringBootApplication @MapperScan("com.itbaizhan.sonwflake.mapper") public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } } 编码编写实体类 User.java@Data public class User { @TableId(type = IdType.ASSIGN_ID)// 雪花算法 private Long id; private String name; private Integer age; private String email; } 编写Mapperpublic interface UserMapper extends BaseMapper<User> { } 添加测试类 @Test void createUser() { User user = new User(); user.setName("张三"); user.setAge(18); user.setEmail("23472@qq.com"); userMapper.insert(user); } -
![测试测试]() 测试测试 browser = await launch() 1 1. 是否以”无头”的模式运行,,即是否显示窗口,默认为 True(不显示) headless=False 1 2. 是否忽略 Https 报错信息,默认为 False ignoreHTTPSErrors=True 1 3. 防止多开导致的假死 dumpio=True 1 4. args常用配置 args=[ # 不显示信息栏,比如:chrome正在受到自动测试软件的控制 '--disable-infobars', # 最大化窗口 "--start-maximized", # 设置UA "--user-agent=Mozilla/5.0......", # 取消沙盒模式,放开权限 "--no-sandbox", # 添加代理 "--proxy-server=http://127.0.0.1:80" ] 1234567891011121314
测试测试 browser = await launch() 1 1. 是否以”无头”的模式运行,,即是否显示窗口,默认为 True(不显示) headless=False 1 2. 是否忽略 Https 报错信息,默认为 False ignoreHTTPSErrors=True 1 3. 防止多开导致的假死 dumpio=True 1 4. args常用配置 args=[ # 不显示信息栏,比如:chrome正在受到自动测试软件的控制 '--disable-infobars', # 最大化窗口 "--start-maximized", # 设置UA "--user-agent=Mozilla/5.0......", # 取消沙盒模式,放开权限 "--no-sandbox", # 添加代理 "--proxy-server=http://127.0.0.1:80" ] 1234567891011121314 -
![此内容被密码保护]()
-
详解no input file specified 三种解决方法 一.IISNoinput file specified方法一:改PHP.ini中的doc_root行,打开ini文件注释掉此行,然后重启IIS 方法二: 请修改php.ini 找到 ; cgi.force_redirect = 1复制去掉前面分号,把后面的1改为0 即 cgi.force_redirect = 0复制二.apache No input file specifiedapache No input filespecified,今天是我们配置apache RewriteRule时出现这种问题,解决办法很简单如下 打开.htaccess 在RewriteRule 后面的index.php教程后面添加一个“?” 完整代码如下.htaccess RewriteEngine on RewriteCond $1 !^(index.php|images|robots.txt) RewriteRule ^(.*)$ /index.php?/$1 [L]复制如果是apache服务器出问题,看看是不是的Apache 把 .php 后缀的文件解析哪里有问题了。 总结 Apache 将哪些后缀作为 PHP 解析。例如,让 Apache 把 .php 后缀的文件解析为PHP。可以将任何后缀的文件解析为 PHP,只要在以下语句中加入并用空格分开。这里以添加一个 .phtml 来示例。 AddType application/x-httpd-php .php .phtml 为了将 .phps教程作为 PHP 的源文件进行语法高亮显示,还可以加上: AddType application/x-httpd-php-source .phps 用通常的过程启动 Apache(必须完全停止 Apache 再重新启动,而不是用 HUP 或者USR1 信号使 Apache 重新加载)。 三.nginx配置遭遇No inputfile specified虚拟机测试nginx 遭遇 Noinput file specified,多方查找终于找到解决办法 1、 php.ini(/etc/php5/cgi/php.ini)的配置中这两项cgi.fix_pathinfo=1 (这个是自己添加的) doc_root=复制2、nginx配置文件/etc/nginx/sites-available/default中注意以下部分location ~ .php$ { fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME /var/www/nginx-default$fastcgi_script_name; include fastcgi_params; }复制上面的部分路径需要根据你主机主目录的实际情况填写 配置完以上部分,重启一下service nginx restart,应该没问题了 以上就是本文的全部内容,希望对大家的学习有所帮助。
-
![爬虫实例(一) —— 5行 Python 代码爬取]() 爬虫实例(一) —— 5行 Python 代码爬取 大家好,我是 Enovo飞鱼,今天分享一个爬虫小案例,小白或者爬虫入门的小伙伴推荐阅读,加油💪。目录前言基本环境配置爬取目标网站爬取内容?实现代码后面我会继续更新爬虫实例,与大家共同学习!希望可以得到大家的支持🙇?前言入门爬虫很容易,几行代码就可以,可以说是学习 Python 最简单的途径。刚开始动手写爬虫,你只需要关注最核心的部分,也就是先成功抓到数据,其他的诸如:下载速度、存储方式、代码条理性等先不管,这样的代码简短易懂、容易上手,能够增强信心。基本环境配置版本:Python3系统:Windows相关模块:pandas、csv爬取目标网站爬取内容??实现代码配置好所需环境后,直接复制即可import pandas as pd for i in range(1,178): # 爬取全部页 tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i)))[3] tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)运行代码结束,至此,3000+ 上市公司的信息,安安静静地躺在 Excel 中A. Pycharm内打开?B. 根据路径打开excel当然,如果你对 Excel 很熟悉的话 ,在 excel 内部也可以很简单的完成爬取上市公司企业数据。即,目前所被讨论的excel自动化,在这篇文章中,就不再讲述其他问题了,多多学习爬虫知识就好!💪后面我会继续更新爬虫实例,与大家共同学习!希望可以得到大家的支持🙇?
爬虫实例(一) —— 5行 Python 代码爬取 大家好,我是 Enovo飞鱼,今天分享一个爬虫小案例,小白或者爬虫入门的小伙伴推荐阅读,加油💪。目录前言基本环境配置爬取目标网站爬取内容?实现代码后面我会继续更新爬虫实例,与大家共同学习!希望可以得到大家的支持🙇?前言入门爬虫很容易,几行代码就可以,可以说是学习 Python 最简单的途径。刚开始动手写爬虫,你只需要关注最核心的部分,也就是先成功抓到数据,其他的诸如:下载速度、存储方式、代码条理性等先不管,这样的代码简短易懂、容易上手,能够增强信心。基本环境配置版本:Python3系统:Windows相关模块:pandas、csv爬取目标网站爬取内容??实现代码配置好所需环境后,直接复制即可import pandas as pd for i in range(1,178): # 爬取全部页 tb = pd.read_html('http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i)))[3] tb.to_csv(r'1.csv', mode='a', encoding='utf_8_sig', header=1, index=0)运行代码结束,至此,3000+ 上市公司的信息,安安静静地躺在 Excel 中A. Pycharm内打开?B. 根据路径打开excel当然,如果你对 Excel 很熟悉的话 ,在 excel 内部也可以很简单的完成爬取上市公司企业数据。即,目前所被讨论的excel自动化,在这篇文章中,就不再讲述其他问题了,多多学习爬虫知识就好!💪后面我会继续更新爬虫实例,与大家共同学习!希望可以得到大家的支持🙇? -
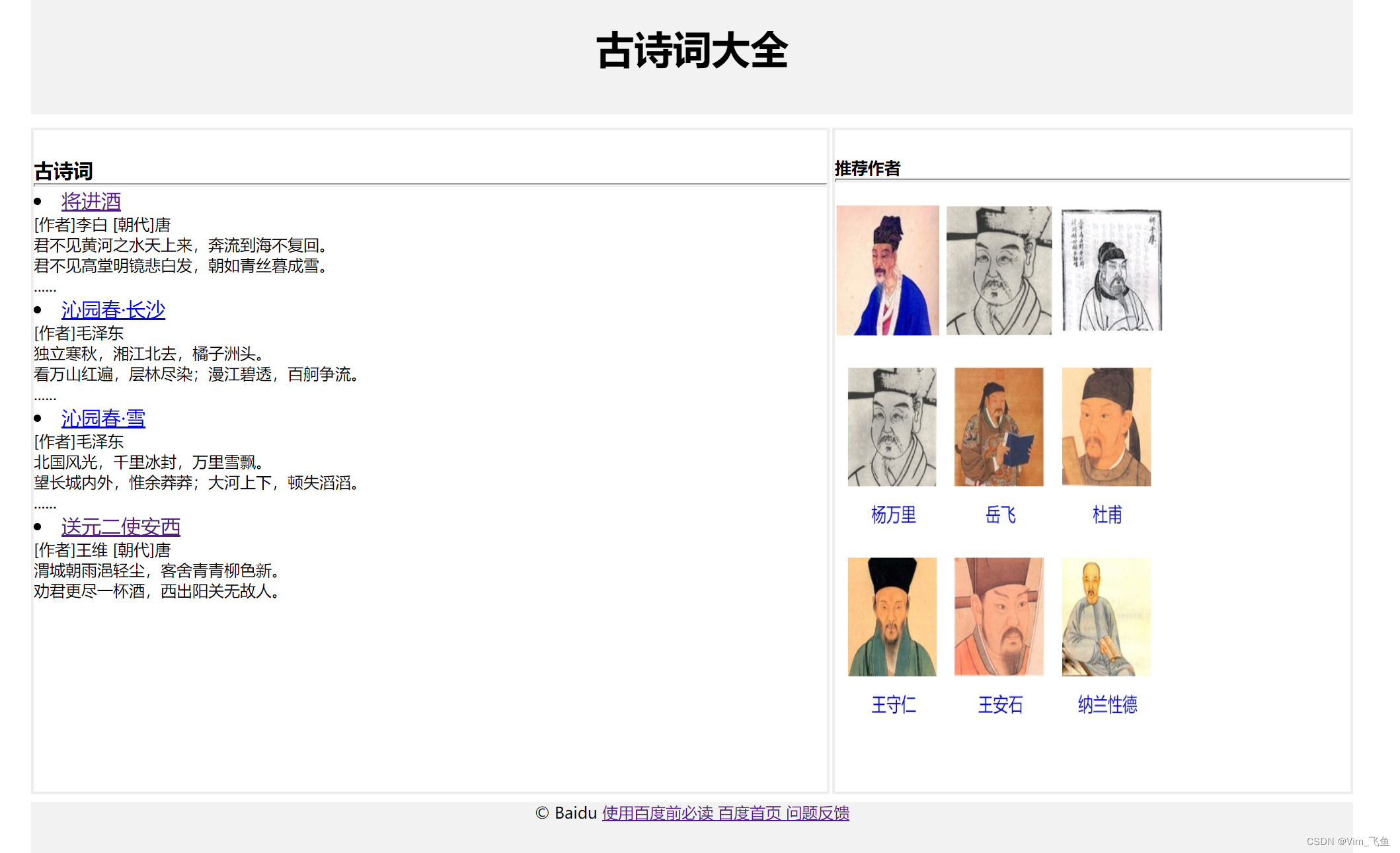
![一个简单的网页设计HTML5作业]() 一个简单的网页设计HTML5作业 前言:HTML5是Web中核心语言HTML的规范,用户使用任何手段进行网页浏览时看到的内容原本都是HTML格式的,在浏览器中通过一些技术处理将其转换成为了可识别的信息。HTML5在从前HTML4.01的基础上进行了一定的改进,虽然技术人员在开发过程中可能不会将这些新技术投入应用,但是对于该种技术的新特性,网站开发技术人员是必须要有所了解的。一直走在路上🏔🐒设计要求:(1)网站页面数量不少于4个,文件命名规范,网站结构要求层次清楚,目录结构清晰,代码缩进规整。(4分)(2)采用HTML结构标记(或div标记)+CSS进行整体布局定位。(5分)(3)网站首页栏目数量不能少于3个,各栏目要能正确链接到相应栏目子页面,同时各栏目页面也能正确返回到网站首页。(3分)(4)网站页面标题、图片图标等要符合网站主题。(2分)(5)网站页面中要有列表。(2分)(6)网站页面中要含有表单(form)。(3分)(7)网站内容应具有原创性,内容充实。(7分)(8)网站整体色系符合视觉习惯,布局合理美观。(4分)🐒首页.html:此次我设计的页面为古诗词页面,含有标题,古诗词,推荐作者,@baidu4块内容?<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> 古诗词大全 </title> <link href="./style.css" rel="stylesheet" type="text/css"> </link> </meta> </meta> </head> <body> <div id="con"> <div id="a"> <h3> 古诗词大全 </h3> </div> <div id="b"> <div id="d"> <br/> <h5> 推荐作者 <br/> <hr/> <br/> </h5> <div> <img alt="刘禹锡" height="100px" position="absolute" src="images/刘禹锡.jpg" width="80px"/> <img alt="杨万里" height="100px" position="absolute" src="images/杨万里.jpg" width="80px"/> <img alt="柳宗元" height="100px" position="absolute" src="images/柳宗元.jpg" width="80px"/> </div> <div> <img alt="" height="300" src="images/shiren.jpg" width="250"> </img> </div> </div> <div id="f"> <br/> <h4> 古诗词 </h4> <hr/> <li> <a href="first.html"> 将进酒 </a> <p> [作者]李白 [朝代]唐 <br/> 君不见黄河之水天上来,奔流到海不复回。 <br/> 君不见高堂明镜悲白发,朝如青丝暮成雪。 <br/> ...... <br/> </p> </li> <li> <a href="second.html"> 沁园春·长沙 </a> <p> [作者]毛泽东 <br/> 独立寒秋,湘江北去,橘子洲头。 <br/> 看万山红遍,层林尽染;漫江碧透,百舸争流。 <br/> ...... <br/> </p> </li> <li> <a href="thired.html"> 沁园春·雪 </a> <p> [作者]毛泽东 <br/> 北国风光,千里冰封,万里雪飘。 <br/> 望长城内外,惟余莽莽;大河上下,顿失滔滔。 <br/> ...... <br/> </p> </li> <li> <a href=""> 送元二使安西 </a> <p> [作者]王维 [朝代]唐 <br/> 渭城朝雨浥轻尘,客舍青青柳色新。 <br/> 劝君更尽一杯酒,西出阳关无故人。 <br/> </p> </li> </div> </div> <div id="c"> <p id="copyright"> ? Baidu <a href="http://www.baidu.com/duty/"> 使用百度前必读 </a> <a href="http://www.baidu.com"> 百度首页 </a> <a href="/s" style="display:none"> 站内搜索 </a> <a href="http://help.baidu.com/newadd?prod_id=8&category=1"> 问题反馈 </a> </p> </div> </div> </body> </html> 🐒分页.html:<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> Enovo将进酒 </title> </meta> </meta> <style typr="text/css"> hr{ background-color: #303841; border: none; height: 1px; width: 100%; } p{ font-family: 楷书; } </style> </head> <body> <div align="center" id="container"> <div class="select"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> <img alt="" height="150px" src="images/qiang.jpg" width="200px"> <div id="contain"> <h1> 将进酒 </h1> <p> 君不见黄河之水天上来,奔流到海不复回。 </p> <p> 君不见高堂明镜悲白发,朝如青丝暮成雪。 </p> <p> 人生得意须尽欢,莫使金樽空对月。 </p> <p> 天生我材必有用,千金散尽还复来。 </p> <p> 烹羊宰牛且为乐,会须一饮三百杯。 </p> <p> 岑夫子,丹丘生,将进酒,杯莫停。 </p> <p> 与君歌一曲,请君为我倾耳听。 </p> <p> 钟鼓馔玉不足贵,但愿长醉不愿醒。 </p> <p> 陈王昔时宴平乐,斗酒十千恣欢谑。 </p> <p> 主人何为言少钱,径须沽取对君酌。 </p> <p> 五花马、千金裘,呼儿将出换美酒,与尔同销万古愁。 </p> </div> </img> </div> <hr/> <div class="exp"> <p> 1.岑夫子:人名 </p> <p> 2.丹丘生:人名 </p> </div> </body> </html> ?<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> Enovo沁园春·长沙 </title> </meta> </meta> <style typr="text/css"> hr{ background-color: #303841; border: none; height: 1px; width: 100%; } p{ font-family: 楷书; } </style> </head> <body> <div align="center" id="container"> <div id="navi"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> <img alt="" height="150px" src="images/chang.jpg" width="200px"> <div id="contain"> <h1> 沁园春·长沙 </h1> <p> 独立寒秋,湘江北去,橘子洲头。 </p> <p> 看万山红遍,层林尽染;漫江碧透,百舸争流。 </p> <p> 鹰击长空,鱼翔浅底,万类霜天竞自由。 </p> <p> 怅寥廓,问苍茫大地,谁主沉浮? </p> <p> 携来百侣曾游,忆往昔峥嵘岁月稠。 </p> <p> 恰同学少年,风华正茂;书生意气,挥斥方遒。 </p> <p> 指点江山,激扬文字,粪土当年万户侯。 </p> <p> 曾记否,到中流击水,浪遏飞舟? </p> </div> </img> </div> <hr/> <div class="exp"> <p> 1.浪遏飞舟: </p> <p> 2.万户侯:古代官职 </p> </div> </body> </html>?<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> Enovo沁园春·雪 </title> </meta> </meta> <style typr="text/css"> hr{ background-color: #303841; border: none; height: 1px; width: 100%; } p{ font-family: 楷书; } </style> </head> <body> <div align="center" id="container"> <div id="navi"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> <img alt="" height="150px" src="images/xue.jpg" width="200px"> <div id="contain"> <h1> 沁园春·雪 </h1> <p> 北国风光,千里冰封,万里雪飘。 </p> <p> 望长城内外,惟余莽莽;大河上下,顿失滔滔。 </p> <p> 山舞银蛇,原驰蜡象,欲与天公试比高。 </p> <p> 须晴日,看红装素裹,分外妖娆。 </p> <p> 江山如此多娇,引无数英雄竞折腰。 </p> <p> 惜秦皇汉武,略输文采;唐宗宋祖,稍逊风骚。 </p> <p> <p> 俱往矣,数风流人物,还看今朝。 </p> </p> </div> </img> </div> <hr/> <div class="exp"> <p> 1.今朝: </p> <p> 2.唐宗宋祖:皇帝 </p> </div> </body> </html>??<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1" name="viewport"> <title> 附页 </title> </meta> </meta> <style type="text/css"> body{ background: url(images/de.jpg); width: 100%; } hr{ background-color: #c7cbd1; border: none; height: 1px; width: 100%; } </style> </head> <body> <form> <div align="center" id="container"> <div id="navi"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> </div> <hr/> <p> 诗词, 是指以古体诗、近体诗和格律词为代表的中国古代传统诗歌。亦是汉字文化圈的特色之一。 </p> <h4> 古诗词考试频率: </h4> <ol> <li> 唐: </li> <ol> <li> 锦瑟【李商隐】 </li> <li> 登高【杜甫】 </li> <li> 雁门太守行【李贺】 </li> </ol> <li> 宋: </li> <ol> <li> 念奴娇·赤壁怀古【苏轼】 </li> <li> 永遇乐·京口北固亭怀古【辛弃疾】 </li> </ol> <hr/> <table align="center" border="5" height="30%" width="50%"> <tr> <!-- 居中加粗 --> <th> 古诗词 </th> <th> 近五年考试频率 </th> </tr> <tr> <td> 念奴娇·赤壁怀古【苏轼】 </td> <td> 4.3星 </td> </tr> <tr> <td> 登高【杜甫】 </td> <td> 3.2星 </td> </tr> </table> <hr/> <p> <h2> 2023高考押题: </h2> </p> <p> <h3> 昵称: </h3> <input name="name" placeholder="请输入您的昵称" size="20" type="text"/> </p> <p> <h3> 古诗词选择: </h3> <select name="古诗词"> <option selected="selected" value="A1"> 锦瑟【李商隐】 </option> <option value="A2"> 念奴娇·赤壁怀古【苏轼】 </option> <option value="A3"> 登高【杜甫】 </option> </select> <!-- 单选框 --> <div> <h3> 考试几率: </h3> <label> <input name="interset" type="radio" value="J1"> 30% </input> </label> <label> <input name="interset" type="radio" value="J2"> 50% </input> </label> <label> <input name="interset" type="radio" value="J3"> 70% </input> </label> <label> <input name="interset" type="radio" value="J4"> 90% </input> </label> </div> </p> <p> 考试心得: </p> <textarea cols="30" id="" name="" rows="10"> </textarea> <p> <input name="确认信息无误" type="radio"> 我已阅读信息并确认无误 </input> </p> <p> <input name="submit" type="submit" value="提交"> <input name="reset" type="reset" value="重置"> </input> </input> </p> </ol> </form> </body> </html> 🐒style.css.exp { text-align: left; } * { margin: 0; padding: 0; } body { font-family: 微软雅黑; font-size: 15px; } #con { margin: 0 auto; width: 1000px; height: 1500px; } #a { height: 100px; margin-bottom: 10px; background: #f2f2f2; text-align: center; font-size: 25px; line-height: 100px; } #b { margin-bottom: 10px; height: 500px; } #d { float: right; width: 390px; height: 500px; background: white; border: 2px solid #eeeeee; } #f { float: left; width: 600px; height: 500px; background: white; border: 2px solid #eeeeee; } #c { height: 150px; background: #f2f2f2; } p { font-size: 10px; } hr { color: #f2f2f2; background: #f2f2f2; height: 1px; } #copyright { text-align: center; }结语:上述内容就是此次html作业的全部内容了,感谢大家的支持,由于初次学习html相信在很多方面存在着不足乃至错误,希望可以得到大家的指正。🙇?(? ?_?)?
一个简单的网页设计HTML5作业 前言:HTML5是Web中核心语言HTML的规范,用户使用任何手段进行网页浏览时看到的内容原本都是HTML格式的,在浏览器中通过一些技术处理将其转换成为了可识别的信息。HTML5在从前HTML4.01的基础上进行了一定的改进,虽然技术人员在开发过程中可能不会将这些新技术投入应用,但是对于该种技术的新特性,网站开发技术人员是必须要有所了解的。一直走在路上🏔🐒设计要求:(1)网站页面数量不少于4个,文件命名规范,网站结构要求层次清楚,目录结构清晰,代码缩进规整。(4分)(2)采用HTML结构标记(或div标记)+CSS进行整体布局定位。(5分)(3)网站首页栏目数量不能少于3个,各栏目要能正确链接到相应栏目子页面,同时各栏目页面也能正确返回到网站首页。(3分)(4)网站页面标题、图片图标等要符合网站主题。(2分)(5)网站页面中要有列表。(2分)(6)网站页面中要含有表单(form)。(3分)(7)网站内容应具有原创性,内容充实。(7分)(8)网站整体色系符合视觉习惯,布局合理美观。(4分)🐒首页.html:此次我设计的页面为古诗词页面,含有标题,古诗词,推荐作者,@baidu4块内容?<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> 古诗词大全 </title> <link href="./style.css" rel="stylesheet" type="text/css"> </link> </meta> </meta> </head> <body> <div id="con"> <div id="a"> <h3> 古诗词大全 </h3> </div> <div id="b"> <div id="d"> <br/> <h5> 推荐作者 <br/> <hr/> <br/> </h5> <div> <img alt="刘禹锡" height="100px" position="absolute" src="images/刘禹锡.jpg" width="80px"/> <img alt="杨万里" height="100px" position="absolute" src="images/杨万里.jpg" width="80px"/> <img alt="柳宗元" height="100px" position="absolute" src="images/柳宗元.jpg" width="80px"/> </div> <div> <img alt="" height="300" src="images/shiren.jpg" width="250"> </img> </div> </div> <div id="f"> <br/> <h4> 古诗词 </h4> <hr/> <li> <a href="first.html"> 将进酒 </a> <p> [作者]李白 [朝代]唐 <br/> 君不见黄河之水天上来,奔流到海不复回。 <br/> 君不见高堂明镜悲白发,朝如青丝暮成雪。 <br/> ...... <br/> </p> </li> <li> <a href="second.html"> 沁园春·长沙 </a> <p> [作者]毛泽东 <br/> 独立寒秋,湘江北去,橘子洲头。 <br/> 看万山红遍,层林尽染;漫江碧透,百舸争流。 <br/> ...... <br/> </p> </li> <li> <a href="thired.html"> 沁园春·雪 </a> <p> [作者]毛泽东 <br/> 北国风光,千里冰封,万里雪飘。 <br/> 望长城内外,惟余莽莽;大河上下,顿失滔滔。 <br/> ...... <br/> </p> </li> <li> <a href=""> 送元二使安西 </a> <p> [作者]王维 [朝代]唐 <br/> 渭城朝雨浥轻尘,客舍青青柳色新。 <br/> 劝君更尽一杯酒,西出阳关无故人。 <br/> </p> </li> </div> </div> <div id="c"> <p id="copyright"> ? Baidu <a href="http://www.baidu.com/duty/"> 使用百度前必读 </a> <a href="http://www.baidu.com"> 百度首页 </a> <a href="/s" style="display:none"> 站内搜索 </a> <a href="http://help.baidu.com/newadd?prod_id=8&category=1"> 问题反馈 </a> </p> </div> </div> </body> </html> 🐒分页.html:<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> Enovo将进酒 </title> </meta> </meta> <style typr="text/css"> hr{ background-color: #303841; border: none; height: 1px; width: 100%; } p{ font-family: 楷书; } </style> </head> <body> <div align="center" id="container"> <div class="select"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> <img alt="" height="150px" src="images/qiang.jpg" width="200px"> <div id="contain"> <h1> 将进酒 </h1> <p> 君不见黄河之水天上来,奔流到海不复回。 </p> <p> 君不见高堂明镜悲白发,朝如青丝暮成雪。 </p> <p> 人生得意须尽欢,莫使金樽空对月。 </p> <p> 天生我材必有用,千金散尽还复来。 </p> <p> 烹羊宰牛且为乐,会须一饮三百杯。 </p> <p> 岑夫子,丹丘生,将进酒,杯莫停。 </p> <p> 与君歌一曲,请君为我倾耳听。 </p> <p> 钟鼓馔玉不足贵,但愿长醉不愿醒。 </p> <p> 陈王昔时宴平乐,斗酒十千恣欢谑。 </p> <p> 主人何为言少钱,径须沽取对君酌。 </p> <p> 五花马、千金裘,呼儿将出换美酒,与尔同销万古愁。 </p> </div> </img> </div> <hr/> <div class="exp"> <p> 1.岑夫子:人名 </p> <p> 2.丹丘生:人名 </p> </div> </body> </html> ?<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> Enovo沁园春·长沙 </title> </meta> </meta> <style typr="text/css"> hr{ background-color: #303841; border: none; height: 1px; width: 100%; } p{ font-family: 楷书; } </style> </head> <body> <div align="center" id="container"> <div id="navi"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> <img alt="" height="150px" src="images/chang.jpg" width="200px"> <div id="contain"> <h1> 沁园春·长沙 </h1> <p> 独立寒秋,湘江北去,橘子洲头。 </p> <p> 看万山红遍,层林尽染;漫江碧透,百舸争流。 </p> <p> 鹰击长空,鱼翔浅底,万类霜天竞自由。 </p> <p> 怅寥廓,问苍茫大地,谁主沉浮? </p> <p> 携来百侣曾游,忆往昔峥嵘岁月稠。 </p> <p> 恰同学少年,风华正茂;书生意气,挥斥方遒。 </p> <p> 指点江山,激扬文字,粪土当年万户侯。 </p> <p> 曾记否,到中流击水,浪遏飞舟? </p> </div> </img> </div> <hr/> <div class="exp"> <p> 1.浪遏飞舟: </p> <p> 2.万户侯:古代官职 </p> </div> </body> </html>?<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1.0" name="viewport"> <title> Enovo沁园春·雪 </title> </meta> </meta> <style typr="text/css"> hr{ background-color: #303841; border: none; height: 1px; width: 100%; } p{ font-family: 楷书; } </style> </head> <body> <div align="center" id="container"> <div id="navi"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> <img alt="" height="150px" src="images/xue.jpg" width="200px"> <div id="contain"> <h1> 沁园春·雪 </h1> <p> 北国风光,千里冰封,万里雪飘。 </p> <p> 望长城内外,惟余莽莽;大河上下,顿失滔滔。 </p> <p> 山舞银蛇,原驰蜡象,欲与天公试比高。 </p> <p> 须晴日,看红装素裹,分外妖娆。 </p> <p> 江山如此多娇,引无数英雄竞折腰。 </p> <p> 惜秦皇汉武,略输文采;唐宗宋祖,稍逊风骚。 </p> <p> <p> 俱往矣,数风流人物,还看今朝。 </p> </p> </div> </img> </div> <hr/> <div class="exp"> <p> 1.今朝: </p> <p> 2.唐宗宋祖:皇帝 </p> </div> </body> </html>??<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta content="width=device-width, initial-scale=1" name="viewport"> <title> 附页 </title> </meta> </meta> <style type="text/css"> body{ background: url(images/de.jpg); width: 100%; } hr{ background-color: #c7cbd1; border: none; height: 1px; width: 100%; } </style> </head> <body> <form> <div align="center" id="container"> <div id="navi"> <a href="index.html"> 首页 | </a> <a href="first.html"> 将进酒 | </a> <a href="second.html"> 沁园春·长沙 | </a> <a href="thired.html"> 沁园春·雪 </a> <hr/> <a href="oddments.html"> 附页 </a> </div> <hr/> </div> <hr/> <p> 诗词, 是指以古体诗、近体诗和格律词为代表的中国古代传统诗歌。亦是汉字文化圈的特色之一。 </p> <h4> 古诗词考试频率: </h4> <ol> <li> 唐: </li> <ol> <li> 锦瑟【李商隐】 </li> <li> 登高【杜甫】 </li> <li> 雁门太守行【李贺】 </li> </ol> <li> 宋: </li> <ol> <li> 念奴娇·赤壁怀古【苏轼】 </li> <li> 永遇乐·京口北固亭怀古【辛弃疾】 </li> </ol> <hr/> <table align="center" border="5" height="30%" width="50%"> <tr> <!-- 居中加粗 --> <th> 古诗词 </th> <th> 近五年考试频率 </th> </tr> <tr> <td> 念奴娇·赤壁怀古【苏轼】 </td> <td> 4.3星 </td> </tr> <tr> <td> 登高【杜甫】 </td> <td> 3.2星 </td> </tr> </table> <hr/> <p> <h2> 2023高考押题: </h2> </p> <p> <h3> 昵称: </h3> <input name="name" placeholder="请输入您的昵称" size="20" type="text"/> </p> <p> <h3> 古诗词选择: </h3> <select name="古诗词"> <option selected="selected" value="A1"> 锦瑟【李商隐】 </option> <option value="A2"> 念奴娇·赤壁怀古【苏轼】 </option> <option value="A3"> 登高【杜甫】 </option> </select> <!-- 单选框 --> <div> <h3> 考试几率: </h3> <label> <input name="interset" type="radio" value="J1"> 30% </input> </label> <label> <input name="interset" type="radio" value="J2"> 50% </input> </label> <label> <input name="interset" type="radio" value="J3"> 70% </input> </label> <label> <input name="interset" type="radio" value="J4"> 90% </input> </label> </div> </p> <p> 考试心得: </p> <textarea cols="30" id="" name="" rows="10"> </textarea> <p> <input name="确认信息无误" type="radio"> 我已阅读信息并确认无误 </input> </p> <p> <input name="submit" type="submit" value="提交"> <input name="reset" type="reset" value="重置"> </input> </input> </p> </ol> </form> </body> </html> 🐒style.css.exp { text-align: left; } * { margin: 0; padding: 0; } body { font-family: 微软雅黑; font-size: 15px; } #con { margin: 0 auto; width: 1000px; height: 1500px; } #a { height: 100px; margin-bottom: 10px; background: #f2f2f2; text-align: center; font-size: 25px; line-height: 100px; } #b { margin-bottom: 10px; height: 500px; } #d { float: right; width: 390px; height: 500px; background: white; border: 2px solid #eeeeee; } #f { float: left; width: 600px; height: 500px; background: white; border: 2px solid #eeeeee; } #c { height: 150px; background: #f2f2f2; } p { font-size: 10px; } hr { color: #f2f2f2; background: #f2f2f2; height: 1px; } #copyright { text-align: center; }结语:上述内容就是此次html作业的全部内容了,感谢大家的支持,由于初次学习html相信在很多方面存在着不足乃至错误,希望可以得到大家的指正。🙇?(? ?_?)? -
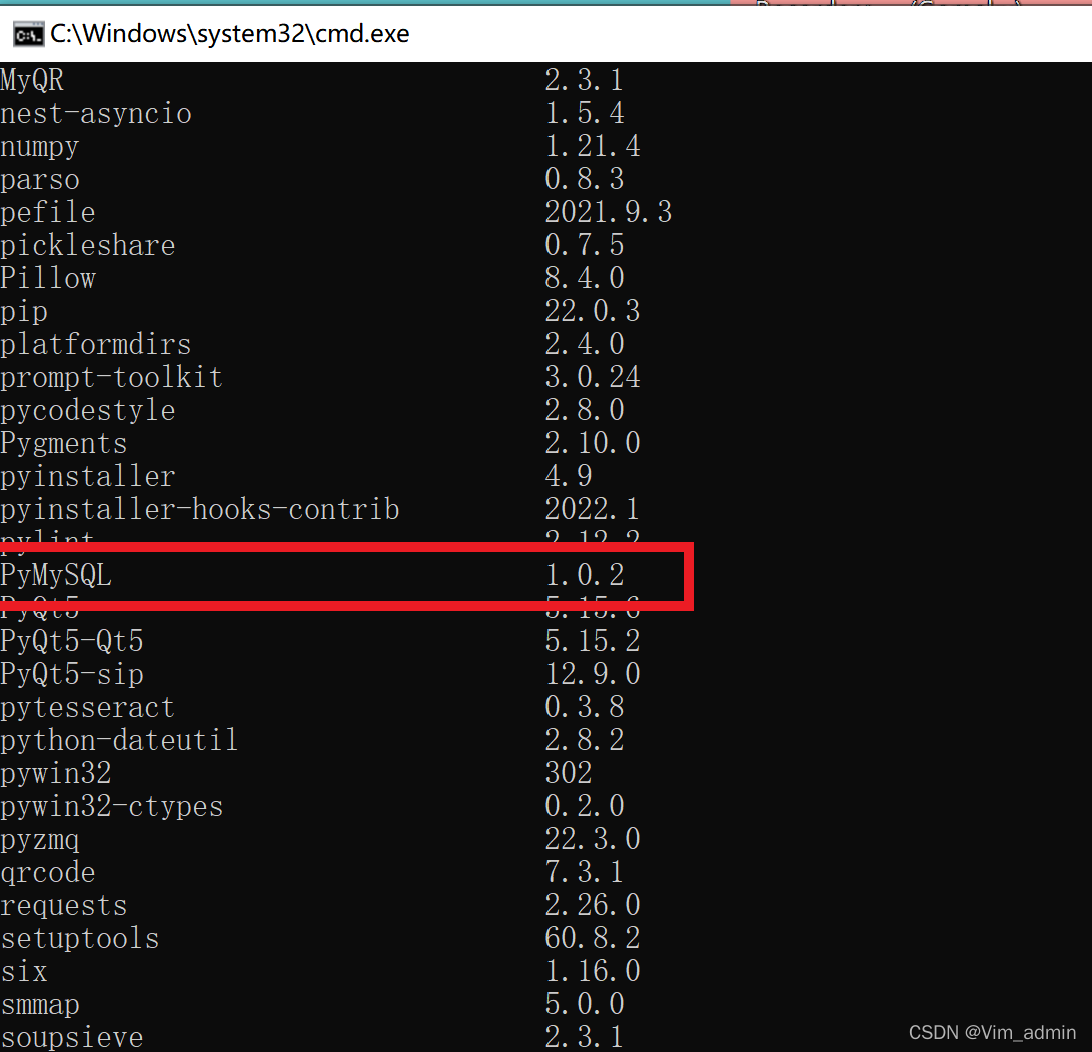
![Python连接MySQL数据库(简单便捷)]() Python连接MySQL数据库(简单便捷) 🐒,本文中,使用到的工具有:Pycharm,Anaconda,MySQL 5.5,spyder(Anaconda)什么是 PyMySQL?PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2 中则使用 mysqldb。一、🏔环境准备1、安装pymysql:进行Python连接mysql数据库之前,需要先安装一下pymysql。直接在终端执行下面的命令即可。(在此处我将指定1.0.2版本)pip install pymysql==1.0.22、查询安装:下载完成后,在终端输入 pip list 即可看到下图:pip list可以看到我们的PyMySQL是1.0.2版本的。3、Anaconda下载pymysql:打开Anaconda,选择 Environments 点击右上方的的搜索框 输入 pymysql?点击方框,即可下载方式一🏔:? ? ? ? 此处我们可以选择 spyder 或者 pycharm 首先为大家介绍一下 spyder 我们只需要直接导入 pymysql 库即可?方式二🏔:?????????4、Pycharm下载pymysql打开 Pycharm 选择文件,点击设置,?下划,选择python解释器,这里我的Pycharm已经配置了Anaconda环境如果没有查询到 pymysql 可以在 Pycharm 终端中下载 pymysql 库以上我们的环境就准备好了,下面我们进行编写程序 ??二、🏔代码编写,连接数据库1、导入数据库表?import pymysql?数据库连接:连接数据库前,请先确认以下事项:连接数据库使用的用户名为 "root" ,密码为 "dai324542",创建了数据库 runoob你可以可以自己设定或者直接使用root用户名及其密码db = pymysql.connect(host='localhost', user='root', password='dai324542', database='runoob', charset='utf8') # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() # 使用 execute() 方法执行 SQL 查询 cursor.execute("SELECT VERSION()") # 使用 fetchone() 方法获取单条数据. data = cursor.fetchone() print ("数据库连接成功!") # 关闭数据库连接 db.close()?2、创建数据库表# 创建表 sql="""CREATE TABLE test ( FIRST_ CHAR(20) NOT NULL, SECOND_ CHAR(20), THIRD_ INT, FOURTH_ CHAR(1), FIFTH_ FLOAT )""" # 运行sql语句 cursor.execute(sql)这里我们所运用的sql语句是不是很熟悉了😊下面即是运行结果了,再mysql中可以刷新看到,我输出了一个提示 victory???3、数据库插入操作此处我只是随便进行了一个举例,通过更改创建表时的操作可以插入不同类型的数据try: sql = "insert into test(FIRST_,SECOND_,THIRD_,FOURTH_,FIFTH_) values ('MAC','MOTH','20','M','2000')" # 运行sql语句 cursor.execute(sql) # 修改 db.commit() # 关闭游标 cursor.close() # 关闭连接 db.close() print("victory!") except: print("false")?4、查询其中一个表的数据# 查询语句 try: cursor = db.cursor() sql = "select * from student" cursor.execute(sql) result = cursor.fetchall() for data in result: print(data) except Exception: print("查询失败")??5、删除表中的一条数据# SQL 删除语句 sql = "DELETE FROM student WHERE Sno='20111107'" try: # 执行SQL语句 cursor.execute(sql) # 向数据库提交 db.commit() except: # 发生错误时回滚 db.rollback() # 关闭连接 db.close() # 成功提示 print("victory!")注意:Python中的MySQL默认事务打开,需要我们手动提交事务,否则操作无效写到这里,这篇博客就又又又结束了,很感谢大家的观看,如果对大家有所帮助希望可以留下一个小小的👍,🙇?。因才学疏浅,如果各位大佬发现其中存在错误,敬请指出,(? ?_?)?!
Python连接MySQL数据库(简单便捷) 🐒,本文中,使用到的工具有:Pycharm,Anaconda,MySQL 5.5,spyder(Anaconda)什么是 PyMySQL?PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2 中则使用 mysqldb。一、🏔环境准备1、安装pymysql:进行Python连接mysql数据库之前,需要先安装一下pymysql。直接在终端执行下面的命令即可。(在此处我将指定1.0.2版本)pip install pymysql==1.0.22、查询安装:下载完成后,在终端输入 pip list 即可看到下图:pip list可以看到我们的PyMySQL是1.0.2版本的。3、Anaconda下载pymysql:打开Anaconda,选择 Environments 点击右上方的的搜索框 输入 pymysql?点击方框,即可下载方式一🏔:? ? ? ? 此处我们可以选择 spyder 或者 pycharm 首先为大家介绍一下 spyder 我们只需要直接导入 pymysql 库即可?方式二🏔:?????????4、Pycharm下载pymysql打开 Pycharm 选择文件,点击设置,?下划,选择python解释器,这里我的Pycharm已经配置了Anaconda环境如果没有查询到 pymysql 可以在 Pycharm 终端中下载 pymysql 库以上我们的环境就准备好了,下面我们进行编写程序 ??二、🏔代码编写,连接数据库1、导入数据库表?import pymysql?数据库连接:连接数据库前,请先确认以下事项:连接数据库使用的用户名为 "root" ,密码为 "dai324542",创建了数据库 runoob你可以可以自己设定或者直接使用root用户名及其密码db = pymysql.connect(host='localhost', user='root', password='dai324542', database='runoob', charset='utf8') # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() # 使用 execute() 方法执行 SQL 查询 cursor.execute("SELECT VERSION()") # 使用 fetchone() 方法获取单条数据. data = cursor.fetchone() print ("数据库连接成功!") # 关闭数据库连接 db.close()?2、创建数据库表# 创建表 sql="""CREATE TABLE test ( FIRST_ CHAR(20) NOT NULL, SECOND_ CHAR(20), THIRD_ INT, FOURTH_ CHAR(1), FIFTH_ FLOAT )""" # 运行sql语句 cursor.execute(sql)这里我们所运用的sql语句是不是很熟悉了😊下面即是运行结果了,再mysql中可以刷新看到,我输出了一个提示 victory???3、数据库插入操作此处我只是随便进行了一个举例,通过更改创建表时的操作可以插入不同类型的数据try: sql = "insert into test(FIRST_,SECOND_,THIRD_,FOURTH_,FIFTH_) values ('MAC','MOTH','20','M','2000')" # 运行sql语句 cursor.execute(sql) # 修改 db.commit() # 关闭游标 cursor.close() # 关闭连接 db.close() print("victory!") except: print("false")?4、查询其中一个表的数据# 查询语句 try: cursor = db.cursor() sql = "select * from student" cursor.execute(sql) result = cursor.fetchall() for data in result: print(data) except Exception: print("查询失败")??5、删除表中的一条数据# SQL 删除语句 sql = "DELETE FROM student WHERE Sno='20111107'" try: # 执行SQL语句 cursor.execute(sql) # 向数据库提交 db.commit() except: # 发生错误时回滚 db.rollback() # 关闭连接 db.close() # 成功提示 print("victory!")注意:Python中的MySQL默认事务打开,需要我们手动提交事务,否则操作无效写到这里,这篇博客就又又又结束了,很感谢大家的观看,如果对大家有所帮助希望可以留下一个小小的👍,🙇?。因才学疏浅,如果各位大佬发现其中存在错误,敬请指出,(? ?_?)?! -
![爬虫实例(二)—— 爬取高清4K图片]() 爬虫实例(二)—— 爬取高清4K图片 大家好,我是 Enovo飞鱼,今天继续分享一个爬虫案例,爬取高清4K图片,加油💪。目录前言增加异常处理增加代码灵活性基本环境配置爬取目标网站分析网站页面具体代码实现图片下载示例感谢支持🙇?+👍前言上篇内容,我们已经了解并惊叹于5行Python代码的强大,今天我们会继续挖掘,并且在原有的基础上进行不断地完善我们将考虑到多方面的内容,例如,增加异常处理,增加代码灵活性,加快爬取速度……增加异常处理由于爬取上百页的网页,中途很可能由于各种问题导致爬取失败,所以增加了 try except 、if else 等语句,来处理可能出现的异常,让代码更健壮。增加代码灵活性初版代码由于固定了 URL 参数,所以只能爬取固定的内容,但是人的想法是多变的,一会儿想爬这个一会儿可能又需要那个,所以可以通过修改 URL 请求参数,来增加代码灵活性,从而爬取更灵活的数据。基本环境配置版本:Python3系统:Windows相关模块:requests,lxml开发工具:Pycharm在这里我使用的是 anaconda ,众所周知这是一个大软件,但是它的环境是比较全面的,在之前的学习中,我们用的是这个软件。anconda,可以理解成运输车,每当下载anconda的时候,里面不仅包含了python,还有180多个库(武器)一同被打包下载下来下载完anconda之后,再也不用一个个下载那些库了。爬取目标网站?分析网站页面有一说一是真的多,看这惊人的页数?接下来就该看看怎么拿到表情包图片的 url 了,首先打开谷歌浏览器,然后点 F12 进入爬虫快乐模式然后完成下图的操作,先点击1号箭头,然后再选中一个表情包即可,红色框中就是我们要爬取的对象,其中表情包的src就在里面?如下图:现在我们就搞清楚了怎么拿到表情包的url了,下一步我们复制 Xpath ,不了解Xpath的小伙伴们可以去学习一下,也是非常好用的在 XML 文档中查找信息的语言。如下图,?至此,我们可以写代码了!!!具体代码实现?相关代码:import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0' } x = input('输入页数: ') for page in range(1, int(x)): if page == 1: url = 'https://pic.netbian.com/4kyingshi/' else: url = 'https://pic.netbian.com/4kyingshi/index_' + str(page) + '.html' response = requests.get(url=url, headers=headers) response.encoding = 'gbk' # 或者gb2312 page_text = response.text tree = etree.HTML(page_text) # 以下三种均可 # li_list = tree.xpath('//div[@id="main"]/div[3]/ul/li[1]/a/img') #li_list = tree.xpath('//div[@class="slist"]/ul/li') li_list = tree.xpath('//div[@id="main"]/div[@class="slist"]/ul/li') for li in li_list: img_src = 'https://pic.netbian.com/' + li.xpath('./a/img/@src')[0] img_name = li.xpath('./a/b/text()')[0] + '.jpg' img = requests.get(url=img_src, headers=headers).content with open('./wwww/' + img_name, 'wb') as fp: fp.write(img) print(img_name + '保存') # //*[@id="main"]/div[3]/ul/li[1]/a # copy xpath 到现在为止,已经拿到了所有的图片的链接和名字,那么就可以开始下载了运行代码,输入你需要下载的页数即可🐒图片下载示例总共是爬了两页图片,做个示例见下图?↓感谢支持🙇?+👍
爬虫实例(二)—— 爬取高清4K图片 大家好,我是 Enovo飞鱼,今天继续分享一个爬虫案例,爬取高清4K图片,加油💪。目录前言增加异常处理增加代码灵活性基本环境配置爬取目标网站分析网站页面具体代码实现图片下载示例感谢支持🙇?+👍前言上篇内容,我们已经了解并惊叹于5行Python代码的强大,今天我们会继续挖掘,并且在原有的基础上进行不断地完善我们将考虑到多方面的内容,例如,增加异常处理,增加代码灵活性,加快爬取速度……增加异常处理由于爬取上百页的网页,中途很可能由于各种问题导致爬取失败,所以增加了 try except 、if else 等语句,来处理可能出现的异常,让代码更健壮。增加代码灵活性初版代码由于固定了 URL 参数,所以只能爬取固定的内容,但是人的想法是多变的,一会儿想爬这个一会儿可能又需要那个,所以可以通过修改 URL 请求参数,来增加代码灵活性,从而爬取更灵活的数据。基本环境配置版本:Python3系统:Windows相关模块:requests,lxml开发工具:Pycharm在这里我使用的是 anaconda ,众所周知这是一个大软件,但是它的环境是比较全面的,在之前的学习中,我们用的是这个软件。anconda,可以理解成运输车,每当下载anconda的时候,里面不仅包含了python,还有180多个库(武器)一同被打包下载下来下载完anconda之后,再也不用一个个下载那些库了。爬取目标网站?分析网站页面有一说一是真的多,看这惊人的页数?接下来就该看看怎么拿到表情包图片的 url 了,首先打开谷歌浏览器,然后点 F12 进入爬虫快乐模式然后完成下图的操作,先点击1号箭头,然后再选中一个表情包即可,红色框中就是我们要爬取的对象,其中表情包的src就在里面?如下图:现在我们就搞清楚了怎么拿到表情包的url了,下一步我们复制 Xpath ,不了解Xpath的小伙伴们可以去学习一下,也是非常好用的在 XML 文档中查找信息的语言。如下图,?至此,我们可以写代码了!!!具体代码实现?相关代码:import requests from lxml import etree headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:94.0) Gecko/20100101 Firefox/94.0' } x = input('输入页数: ') for page in range(1, int(x)): if page == 1: url = 'https://pic.netbian.com/4kyingshi/' else: url = 'https://pic.netbian.com/4kyingshi/index_' + str(page) + '.html' response = requests.get(url=url, headers=headers) response.encoding = 'gbk' # 或者gb2312 page_text = response.text tree = etree.HTML(page_text) # 以下三种均可 # li_list = tree.xpath('//div[@id="main"]/div[3]/ul/li[1]/a/img') #li_list = tree.xpath('//div[@class="slist"]/ul/li') li_list = tree.xpath('//div[@id="main"]/div[@class="slist"]/ul/li') for li in li_list: img_src = 'https://pic.netbian.com/' + li.xpath('./a/img/@src')[0] img_name = li.xpath('./a/b/text()')[0] + '.jpg' img = requests.get(url=img_src, headers=headers).content with open('./wwww/' + img_name, 'wb') as fp: fp.write(img) print(img_name + '保存') # //*[@id="main"]/div[3]/ul/li[1]/a # copy xpath 到现在为止,已经拿到了所有的图片的链接和名字,那么就可以开始下载了运行代码,输入你需要下载的页数即可🐒图片下载示例总共是爬了两页图片,做个示例见下图?↓感谢支持🙇?+👍